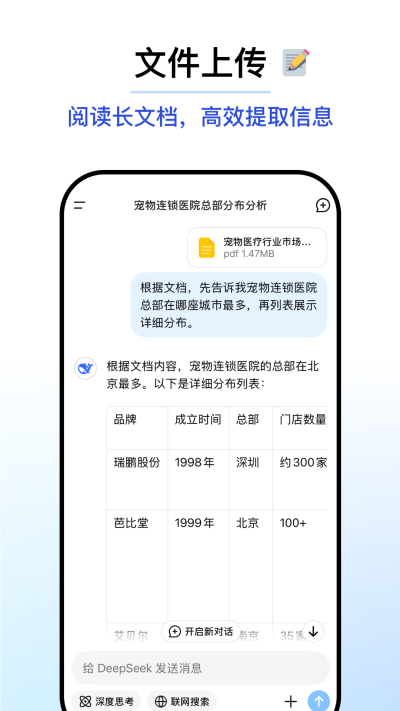
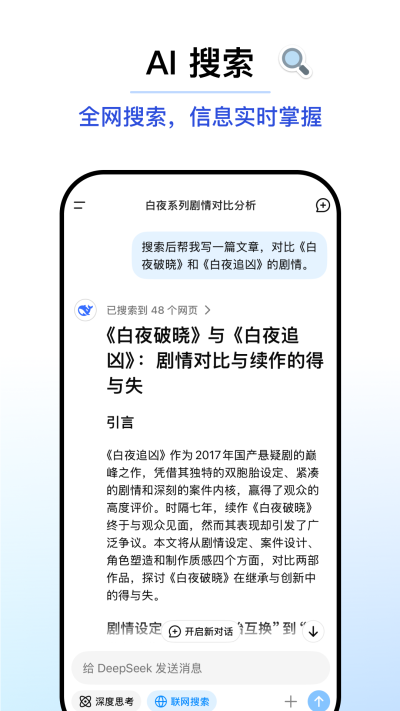
迪普西克即是DeepSeek提供多领域知识解答,包括科技、教育、生活、编程等,支持复杂逻辑推理与数学计算,生成文章、报告、故事、代码等结构化内容,可处理表格数据、生成可视化图表、自动化数据清洗与报告总结,支持定制化模型训练,提供API接口,便于集成到第三方应用。
迪普西克官网
https://chat.deepseek.com
1.打开迪普西克,点击左上角的菜单选项。

2.在菜单界面中,点击下方的头像按钮。

3.在账户界面中点击联系我们的选项。
4.进入界面后点击联系支持人员的按钮。
5.最后可以在下方输入相应问题即可联系客服。
DeepSeek-V3 和 DeepSeek-R1 是深度求索(DeepSeek)公司开发的两款人工智能模型,尽管它们基于相似的技术框架(如混合专家架构 MoE),但在设计目标、训练方法、性能表现和应用场景上存在显著差异。以下是两者的主要区别:
1. 模型定位与核心能力
● DeepSeek-V3
● 定位为通用型大语言模型,专注于自然语言处理(NLP)、知识问答和内容生成等任务。
● 采用混合专家架构(MoE),每次推理仅激活 370 亿参数(总参数为 6710 亿),显著降低计算成本。
● 优势在于高效的多模态处理能力(文本、图像、音频、视频)和较低的训练成本(557.6 万美元,仅需 2000 块 H800 GPU)。
● 在基准测试中表现接近 GPT-4o 和 Claude-3.5-Sonnet,但更注重综合场景的适用性。
● DeepSeek-R1
● 专为复杂推理任务设计,强化在数学、代码生成和逻辑推理领域的性能。
● 基于 DeepSeek-V3 架构,通过大规模强化学习(RL)和冷启动技术优化推理能力,无需大量监督微调(SFT)。
● 在数学竞赛(如 AIME 2024)和编码任务(如 Codeforces)中表现优异,超越 OpenAI 的 o1 系列模型。
2. 训练方法与技术创新
● DeepSeek-V3
● 采用传统的预训练-监督微调范式,结合混合专家架构(MoE)和负载均衡技术,优化计算效率。
● 引入多令牌预测(MTP)技术,加快推理速度并提高任务表现。
● DeepSeek-R1
● 完全摒弃监督微调(SFT),直接通过强化学习(RL)从基础模型中激发推理能力。
● 核心技术包括 GRPO 算法(群组相对策略优化)和两阶段 RL,结合冷启动数据优化初始模型。
● 通过自我进化能力,模型在训练中自然涌现反思、长链推理等高级行为。
Q:迪普西克的响应速度如何?
A:通常1-3秒内返回结果,复杂任务可能稍长。
Q:迪普西克是否支持本地化部署?
A:企业版支持私有化部署,保障数据安全。
Q:迪普西克生成内容可能存在错误怎么办?
A:建议交叉验证关键信息,或通过“反馈”功能提交修正建议。
Q:迪普西克如何保障隐私安全?
A:默认不存储对话记录,数据传输采用SSL加密。
Q:迪普西克是否支持多语言?
A:支持中、英、日、法等主流语言。
1.低延迟,适应实时交互场景,支持长对话记忆,保持上下文连贯性。
2.基于自研大模型,优化算法提升准确性。
3.适用于教育、企业、开发、个人学习等多场景。
v1.0.13版本
- 修复部分已知问题